🐩 Teaching a Model 37 Dog and Cat Breeds


I find it hard not to be intimidated when a neural network model can differentiate between dog and cat breeds that I honestly just cannot. But instead, I just get really excited about the possibilities and potential and am just grateful for all the work that so many amazing humans have put into this field to get us this far.
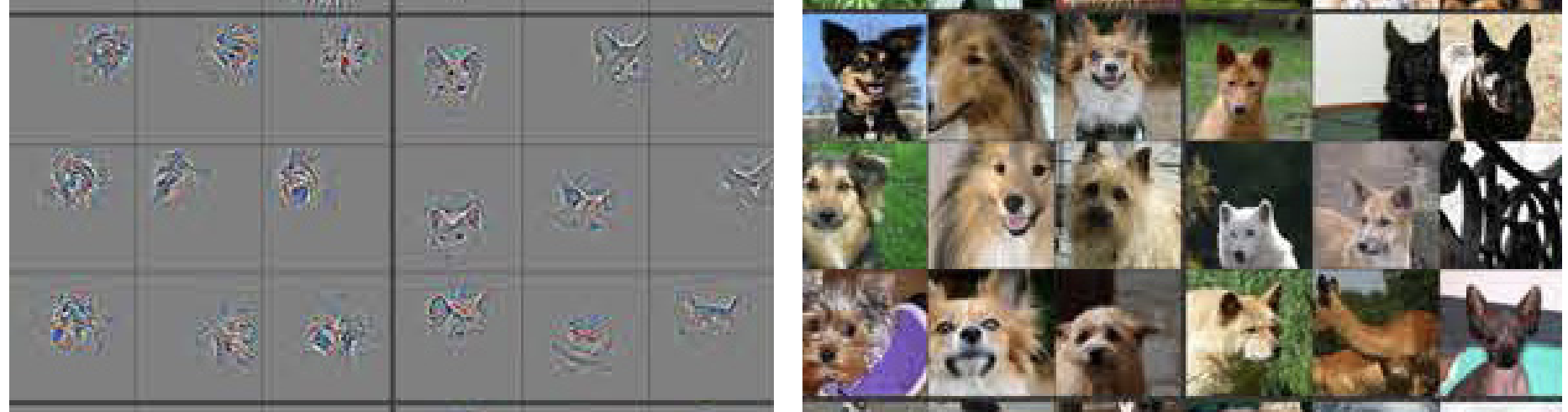
This project was incredibly interesting. Getting deep into the way neural networks see and discern image features is utterly fascinating to me. For example, the image below shows the features that this particular model began to find in dogs' faces in convolutional layer 5, little doggy snouts! For the entire paper this image comes from, click here. I highly suggest checking it out, as it is a fantastic source to gain a more complete understanding of this process and conceptualize what the model is "seeing".
For this project, I decided to train two different Resnet models, Resnet-34 and Resnet-50. At first, I had only worked with Resnet-34, and it reached close to 95% accuracy at times. I was just starting to write this most, and then curiosity won me over, and I decided to give Resnet-50 a go as well, mainly because I have always found it to be a perfect layer depth for getting the best results. And since there's a nice GPU available in-home, I figured I might as well. Unfortunately, while Resnet-50 did reach a higher percentage accuracy earlier on in training, it did not outshine Resnet-34.
There are a number of aspects of comparing models that I find very helpful sometimes, depending on the data I am working with. I have noticed that comparing the results, predictions, and overall ways that different models view the data tells me a great deal about the data and also about the model itself. For example, in the two cells below, I have extracted every pair of breeds that each model confused with one another if it experienced that confusion 3 or more times. And for the most part, it looks like both models ran into the same issues with mistaking one breed for the other.
But where they differ is what I find the most interesting. I find that the more I can imagine and see in my mind's eye these errors and visualize what is going wrong, the more I can truly understand how the model "sees". And I feel that bridging this gap between human mind and machine mind is one of the major next steps that we in this field have to attempt with more focus on imagination. Numbers alone will never be able to truly communicate this information to the human mind. A lot of what still holds us back in the field, it seems, is the communication barrier from machine to human. And that is why I LOVE projects like Loss Landscape, a project by Javier Ideami.
I found Ideami's Loss Landscapes while working on this project. I was searching the almighty interwebs, looking for ways to help my mind more clearly and visually take in everything that my model was throwing back at me. Intuitively, it is clear that everything I need to know to more effectively work with the technology is readily available if I can just bridge that gap between myself and the model. Sometimes I can "feel" that the model is telling me something, and I am not quite sure the message. So I really appreciate Ideami's work on making that exact endeavor, to perceive the previously impercetible, a reality. And of course, Javier is a Fast.ai alumnus. I was not at all surprised to make that discovery.
Check out this full project here:
Interactive Jupyter Notebook | PDF Version
Or scroll through the notebook here 👇