📚 SQL-la-la-la!


I must admit: having spent so much time with Pandas and all its eloquence when dealing with data, it was hard for me to go back and brush up on my SQL. But I did it. It is just one of those things that I need to be good at, right? No problem! I got this! So here is a little walk through my journey with SQL.
I used Data.World for this project, and while it was not 100% ideal, it was definitely a very nice tool for working with SQL and databases. This project centers around a database of over 10,000 employees containing all of their information in the company's database as well as a detailed dates database. First, I explored the employee records and got to know the layout.
First, let's just get a look at all the employees with:
SELECT * FROM employees
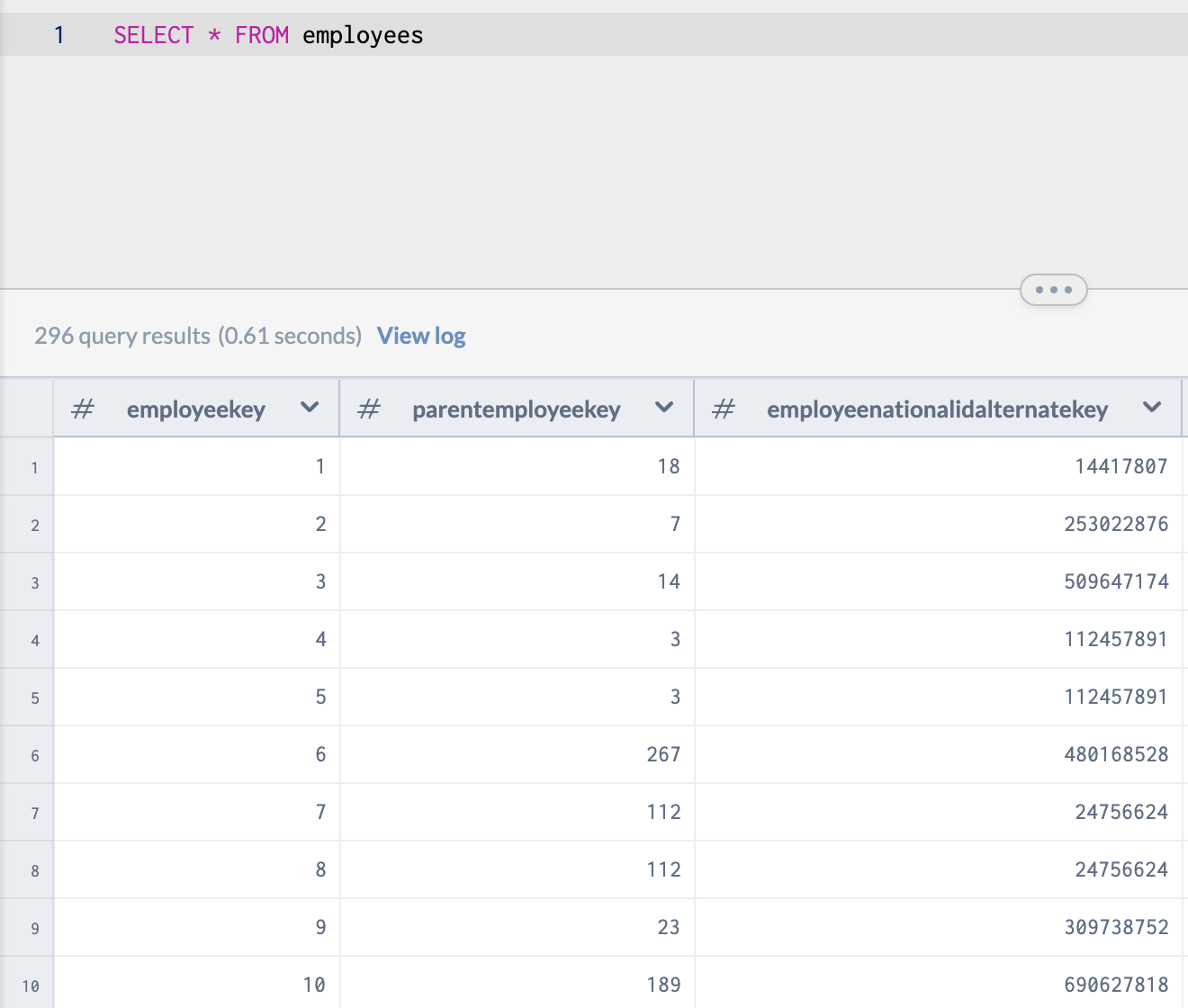
The first objective: Let's find all the range of all the employee start dates from the first start date to the latest end date contained within the database.
SELECT min(employees.startdate), max(employees.startdate)
FROM employees
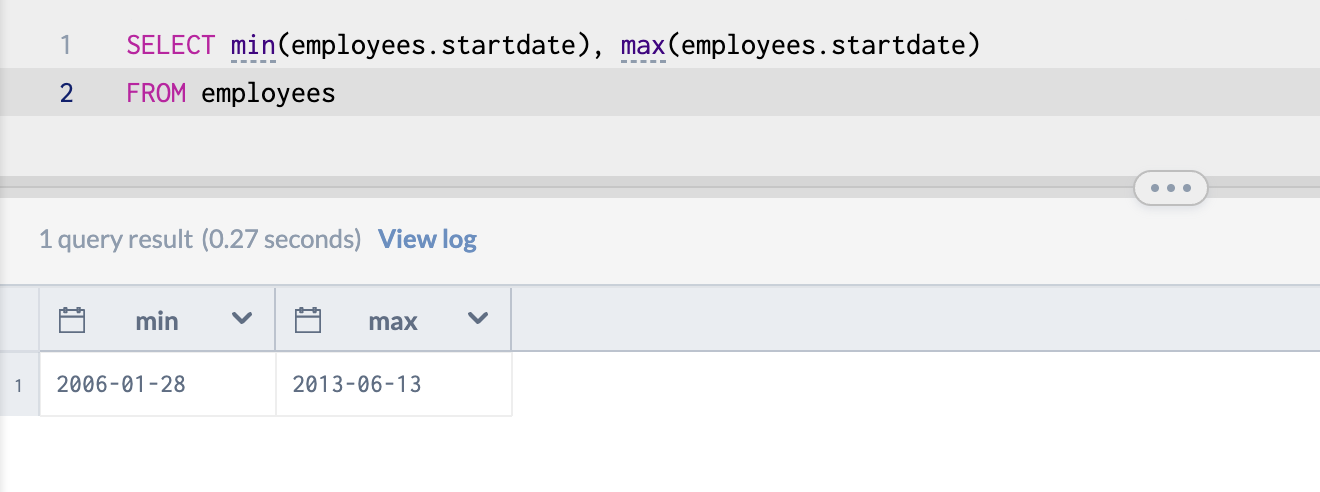
Next, how about a list of the counts of the employee start dates organized by year and month?
SELECT MONTH(employees.startdate), YEAR(employees.startdate), COUNT(1)
FROM employees
GROUP BY MONTH(employees.startdate), YEAR(employees.startdate)
ORDER BY 2, 1
How do we find out how many employees were active on a given date, you ask?
SELECT *
FROM employees
WHERE employees.startdate >= '2008-07-01'
AND (employees.enddate <= '2008-07-01'
OR
employees.enddate is NULL)
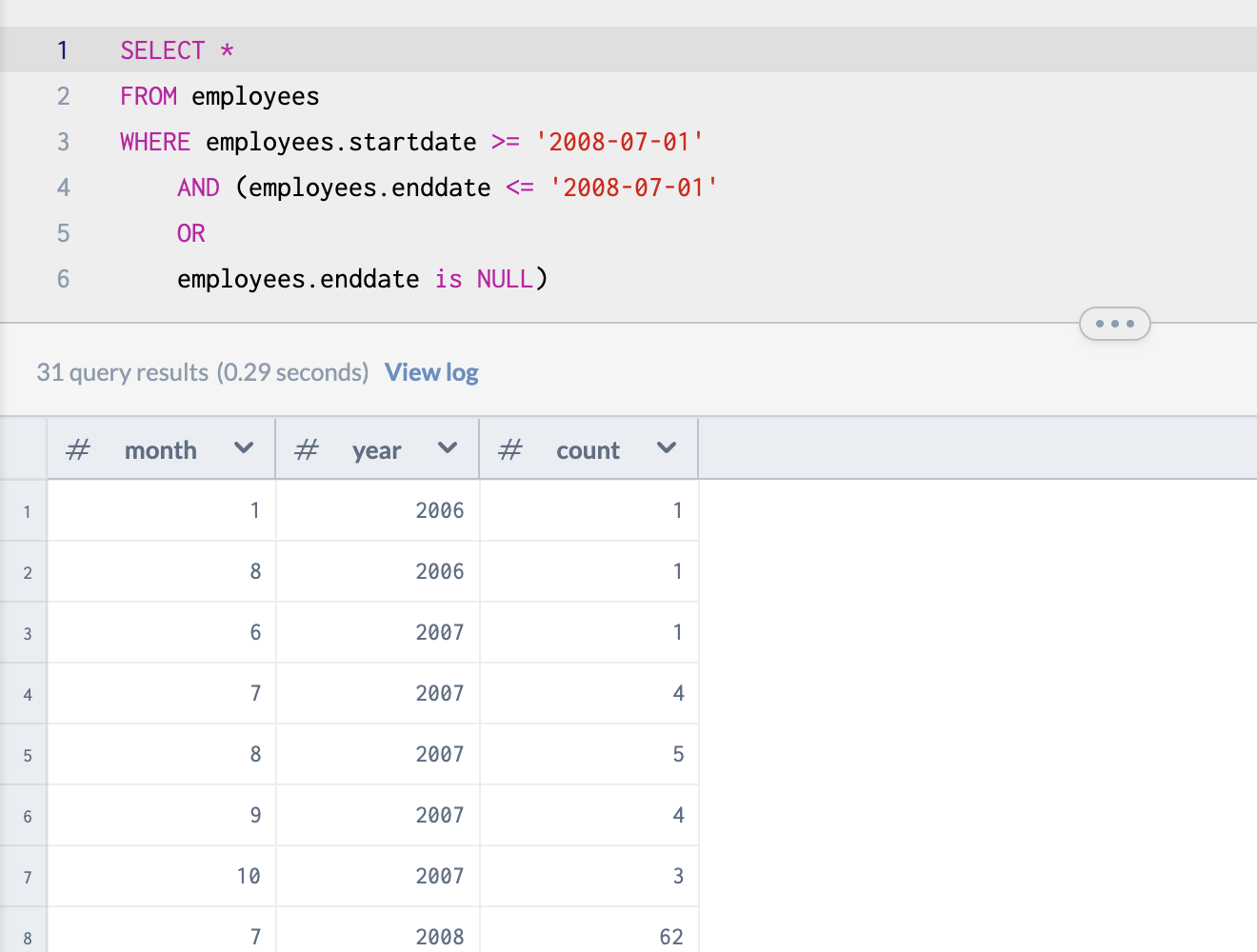
What if instead of * for all of the employees, we just ask for a total count of the employees on the given date?
SELECT COUNT(1)
FROM employees
WHERE employees.startdate >= '2008-07-01'
AND (employees.enddate <= '2008-07-01'
OR
employees.enddate is NULL)
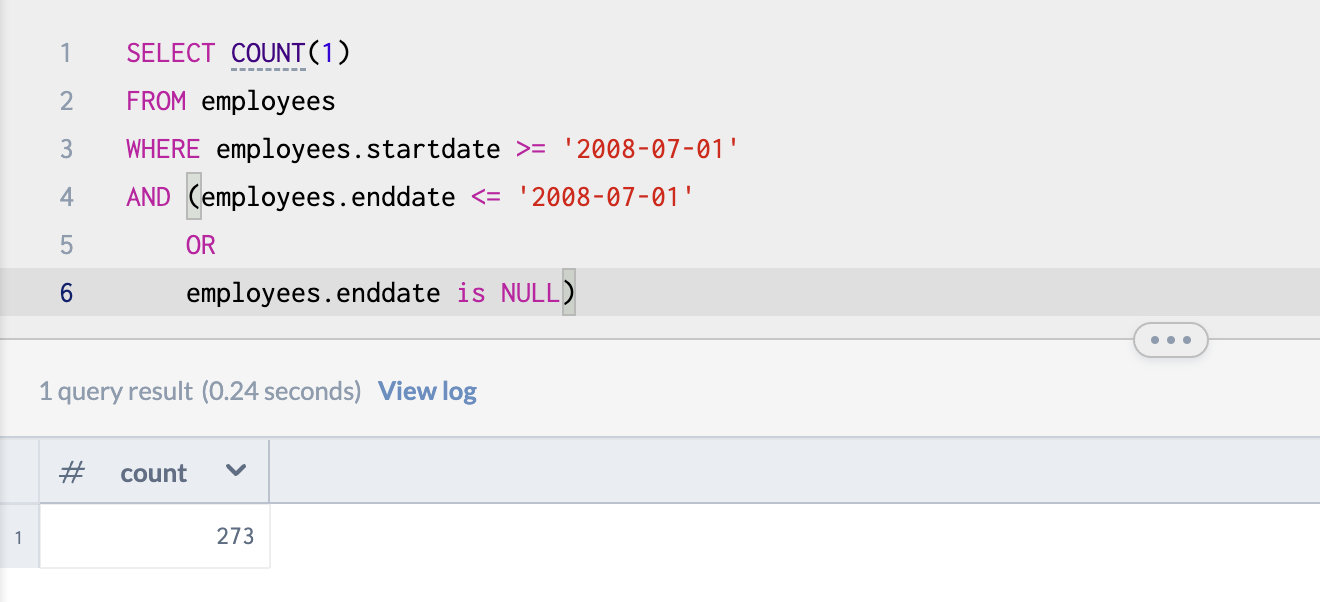
One tricky aspect to the datatbase is that any current employee has no enddate listed. So any search we perform with a date that involves that field will not return to us any current employees.
SELECT dates.datekey, employees.startdate, employees.enddate, COUNT(1)
FROM employees CROSS JOIN dates
WHERE dates.datekey BETWEEN employees.startdate AND employees.enddate
GROUP BY dates.datekey, employees.startdate, employees.enddate
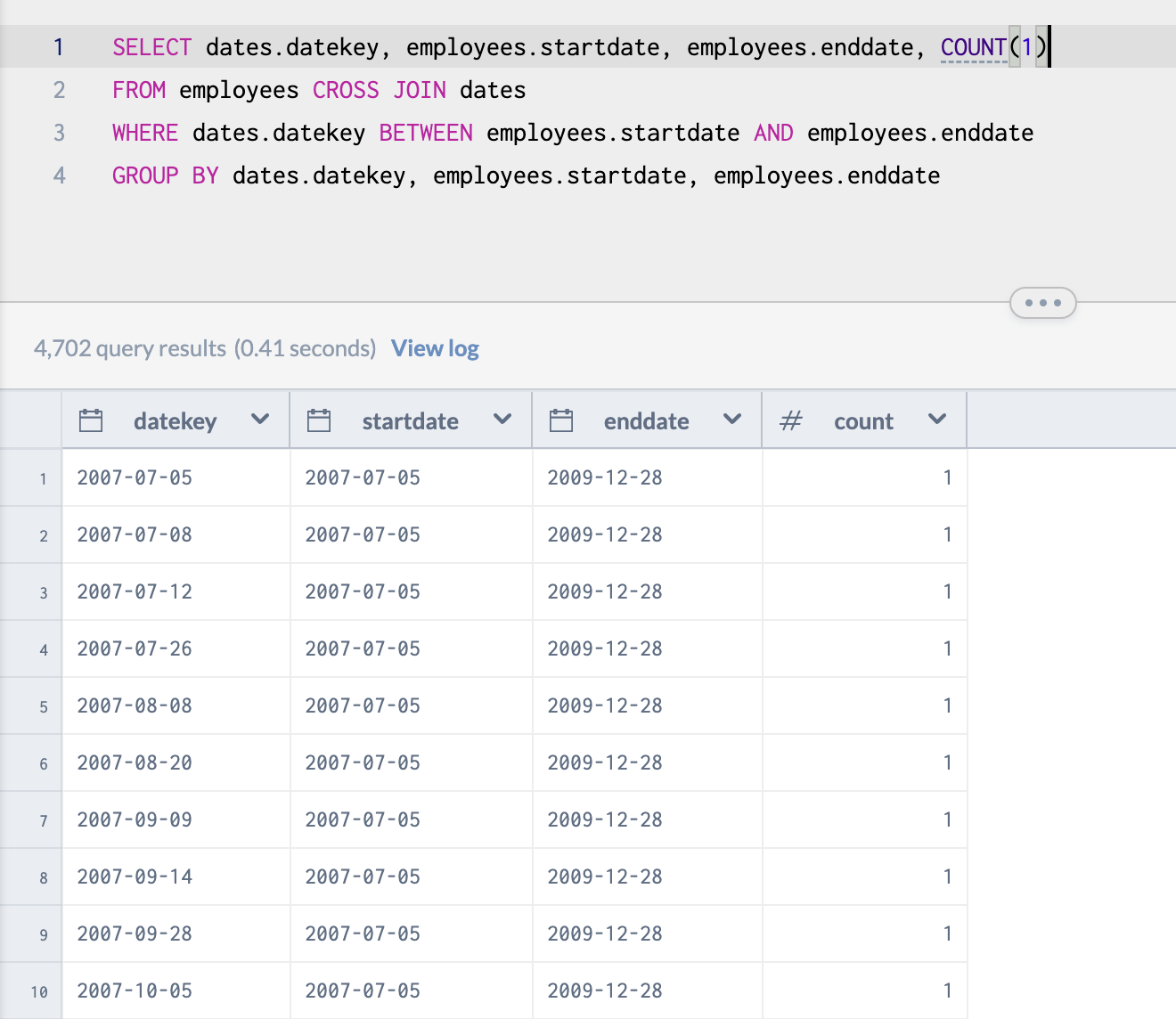
This is because for every employee in the company currently, their enddate field reads No data. What if we wanted a date instead? Perhaps a date that for all intents and purposes is the time equivalent to infinity? Let's make that the end of the year 9999. It simply looks daunting and confusing though!
SELECT dates.datekey, employees.startdate, IF(employees.enddate is null, "9999-12-31", employees.enddate) edate, employees.*
FROM employees cross join dates
WHERE dates.datekey >= employees.startdate
AND (dates.datekey <= employees.enddate
OR
employees.enddate IS NULL)
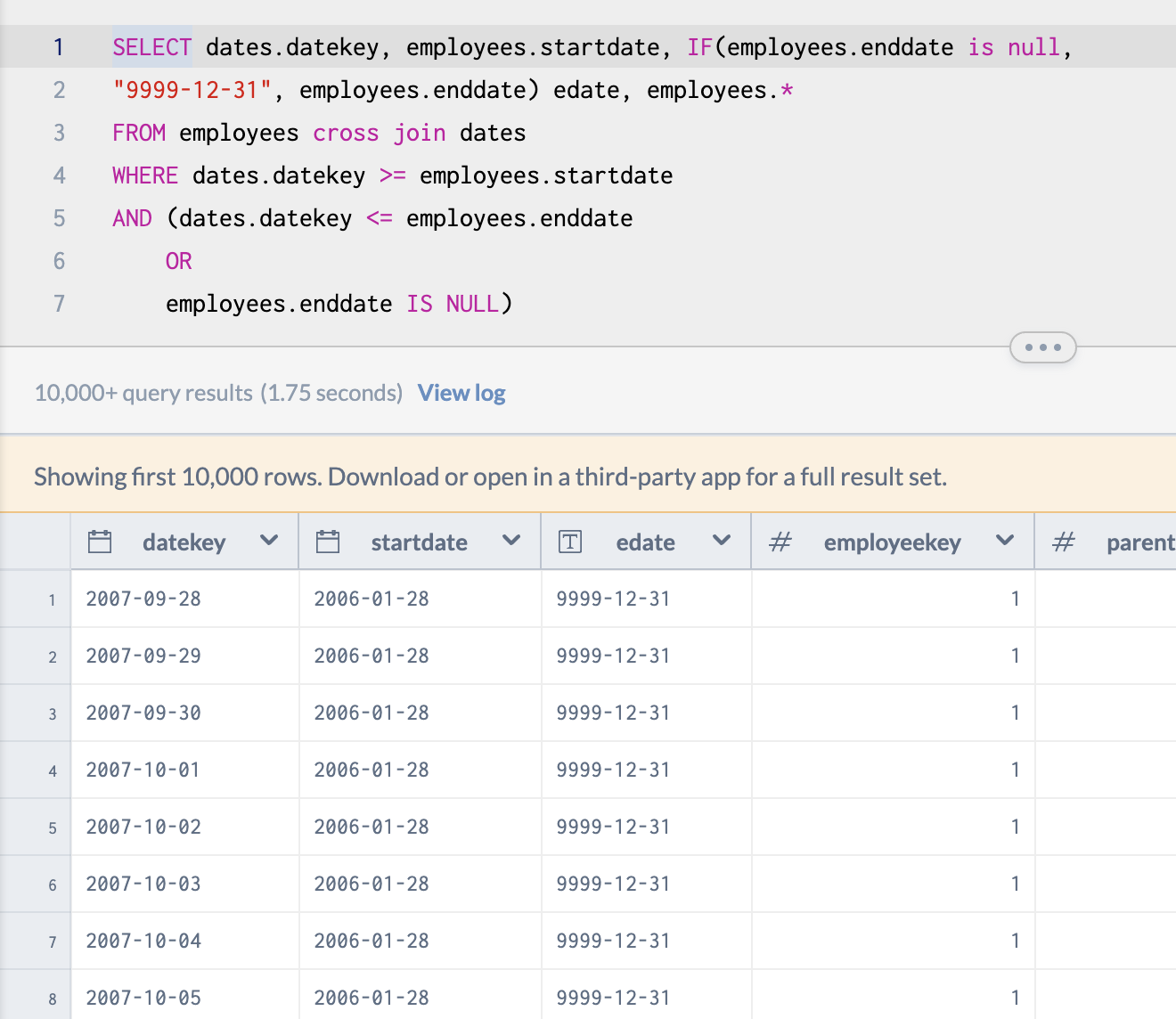
Suppose we want to find a count of all the employees who were on the payroll for any given month? How would we do that? Unfortunately, this way gives us a count for every employee for every day of the given month. So the counts we are returning are approximately 30 times higher than the count we were going for.
SELECT DATE_TRUNC(dates.datekey, "month") AS mnt, COUNT(1)
FROM employees CROSS JOIN dates
WHERE dates.datekey >= employees.startdate
AND (dates.datekey <= employees.enddate
OR
employees.enddate IS NULL)
GROUP BY DATE_TRUNC(dates.datekey, "month")
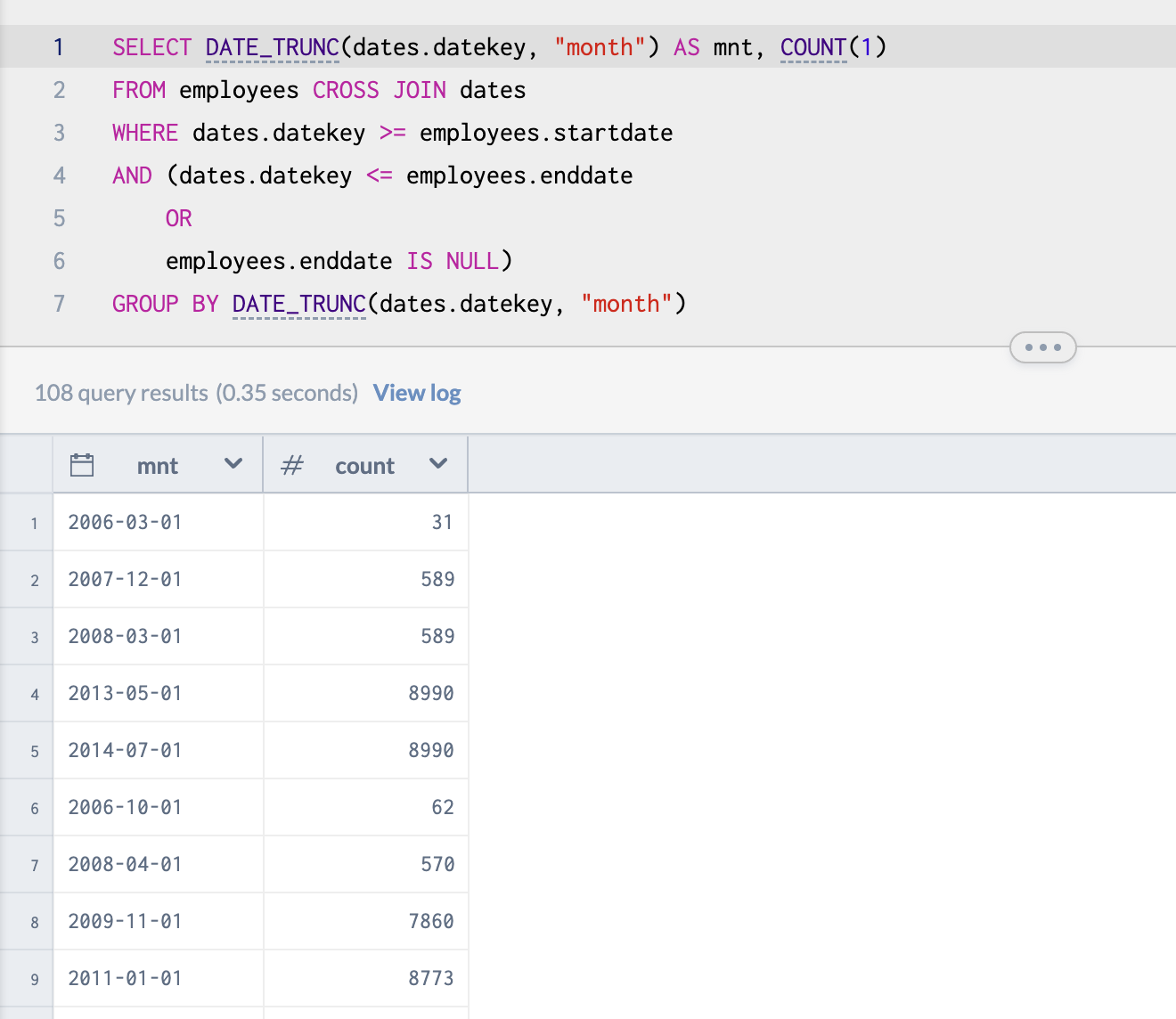
This code will, by a long and arduous road, get us the last day of any given month. We can use this to get the total employee count by month.
SELECT
dates.datekey,
DATE_TRUNC(dates.datekey, "month") month,
DATE_ADD(DATE_TRUNC(dates.datekey, "month"), 1, "month") next_month,
DATE_ADD(DATE_ADD(DATE_TRUNC(dates.datekey, "month"), 1, "month"), -1, "day") eomonth
FROM dates
LIMIT 10;
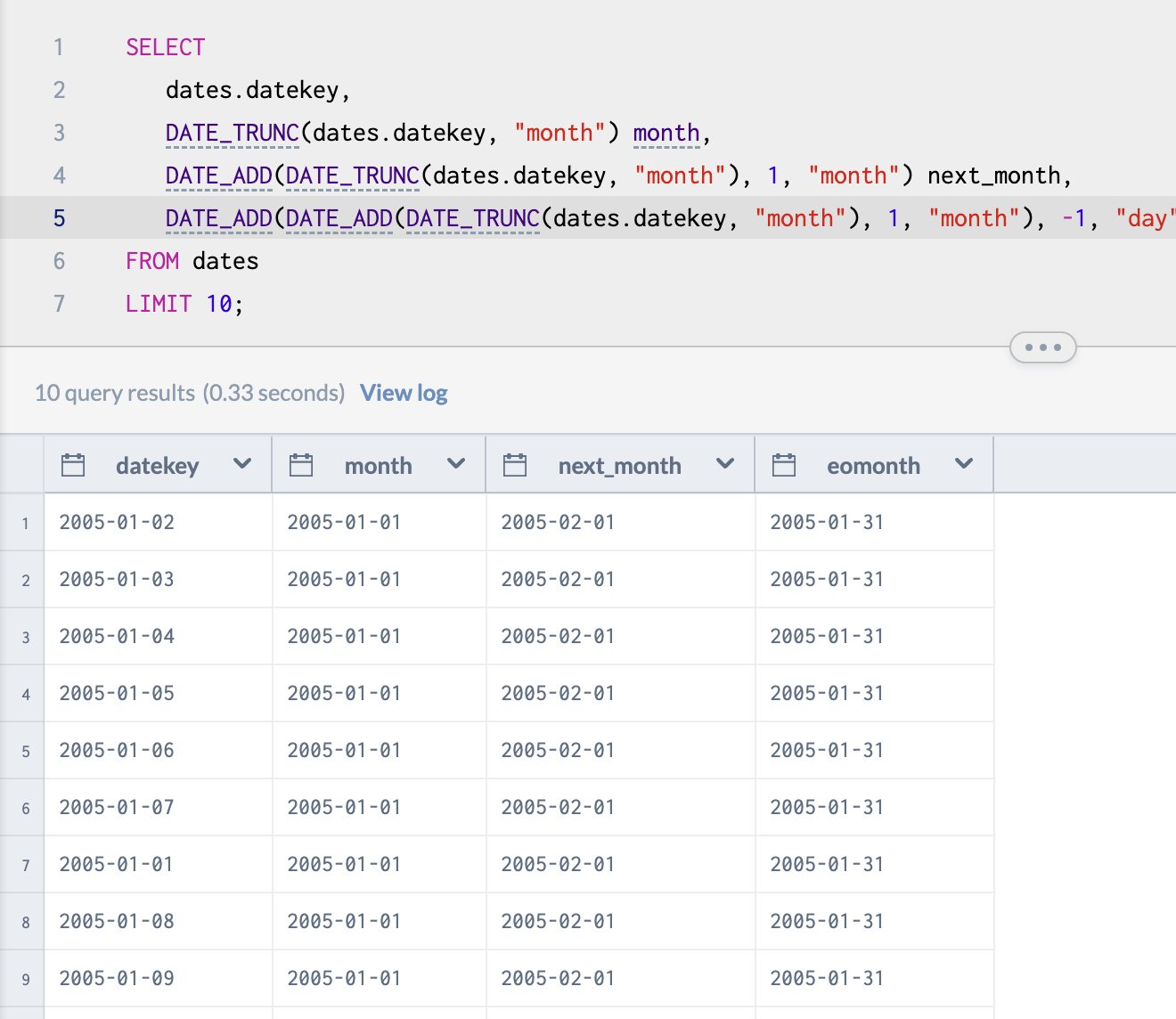
And with this code, we will get the total employee count for each month, compiled on the final day of each month. The way we do this is conceptually simply, even though the code makes it look like a brain-full.
Let's start with the previous bit of code that gets us the final day of the month. We will call it our datelist, or dl for short.
WITH `dl` AS (
SELECT DISTINCT
CAST(DATE_ADD(DATE_ADD(DATE_TRUNC(dates.datekey, "month"), 1,
"month"), -1, "day") AS DATE) eomonth
FROM dates
)
Next, we will use this as a pseudo-table in which we will find the count of employees for each month, registered at the last day of the month via a subquery. We will CROSS JOIN the dates pseudo-table with the employees table and return the employees who were employed during each month in the pseudo-table.
SELECT dl.eomonth, COUNT(1)
FROM employees CROSS JOIN `dl` AS dl
WHERE dl.eomonth >= employees.startdate
AND (dl.eomonth <= employees.enddate
OR
employees.enddate IS NULL)
GROUP BY dl.eomonth
ORDER BY dl.eomonth
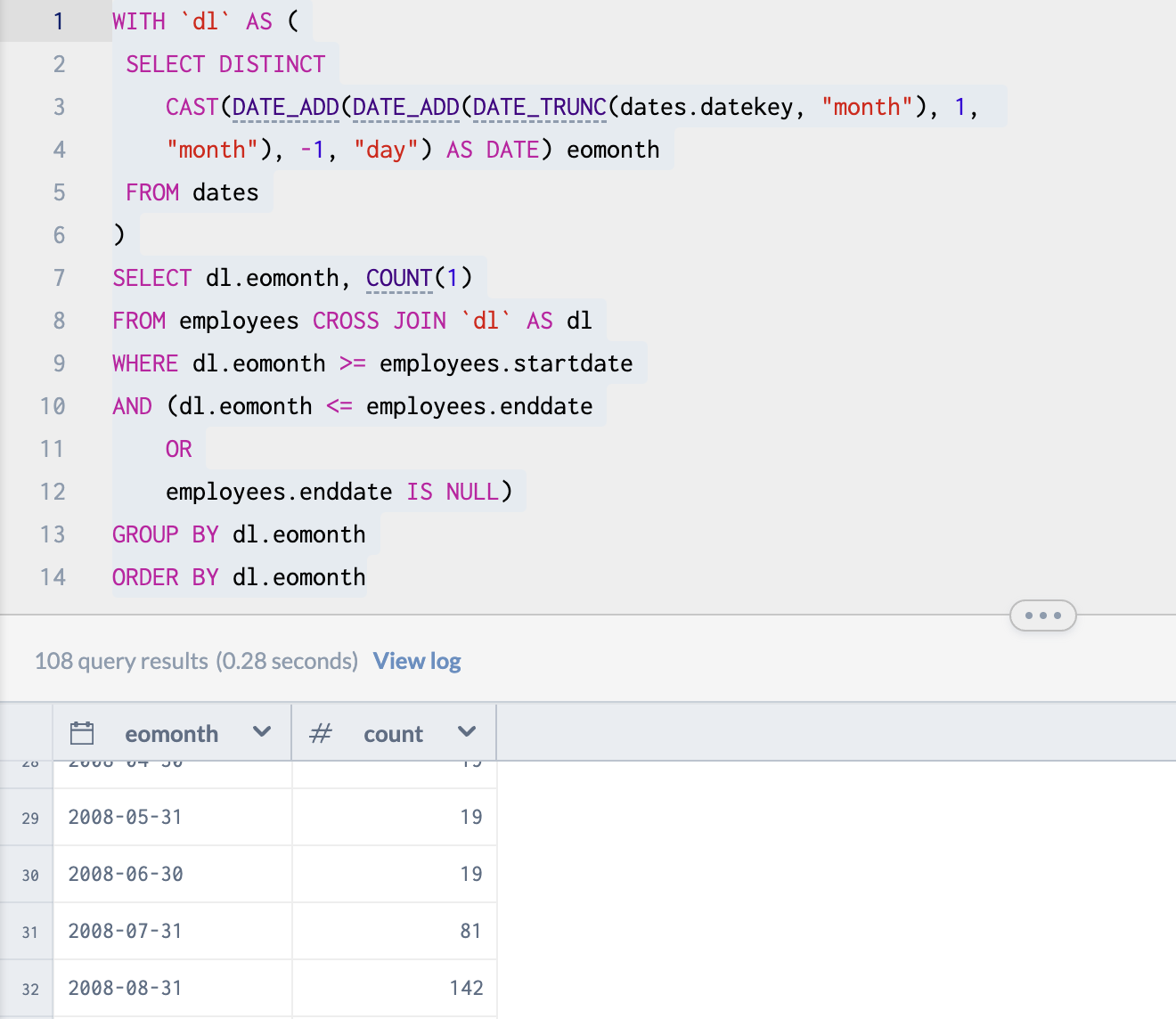
Tada! Wasn't that a nice little visit with SQL? It does feel a little limited and antiquated having spent so much time with Pandas since the last tryst I had with SQL. But it is an important color to have in one's skill palette. And it really is not that challenging to get comfortable with once the ice has been broken!
Special thanks to Ben Sullins at Free the Data Academy and his data analysis instruction!